Abstract
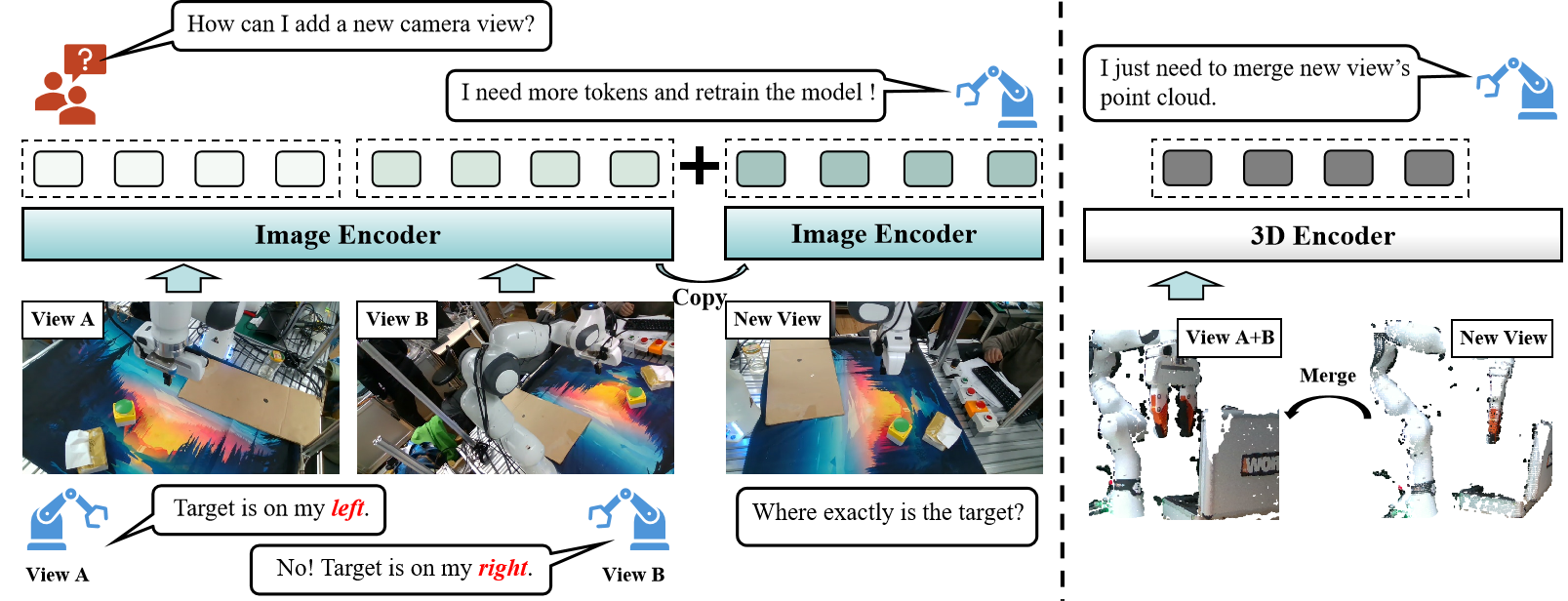
Comparison of 2D and 3D Modalities: CLAR leverages 3D point clouds to resolve multi-view ambiguity.
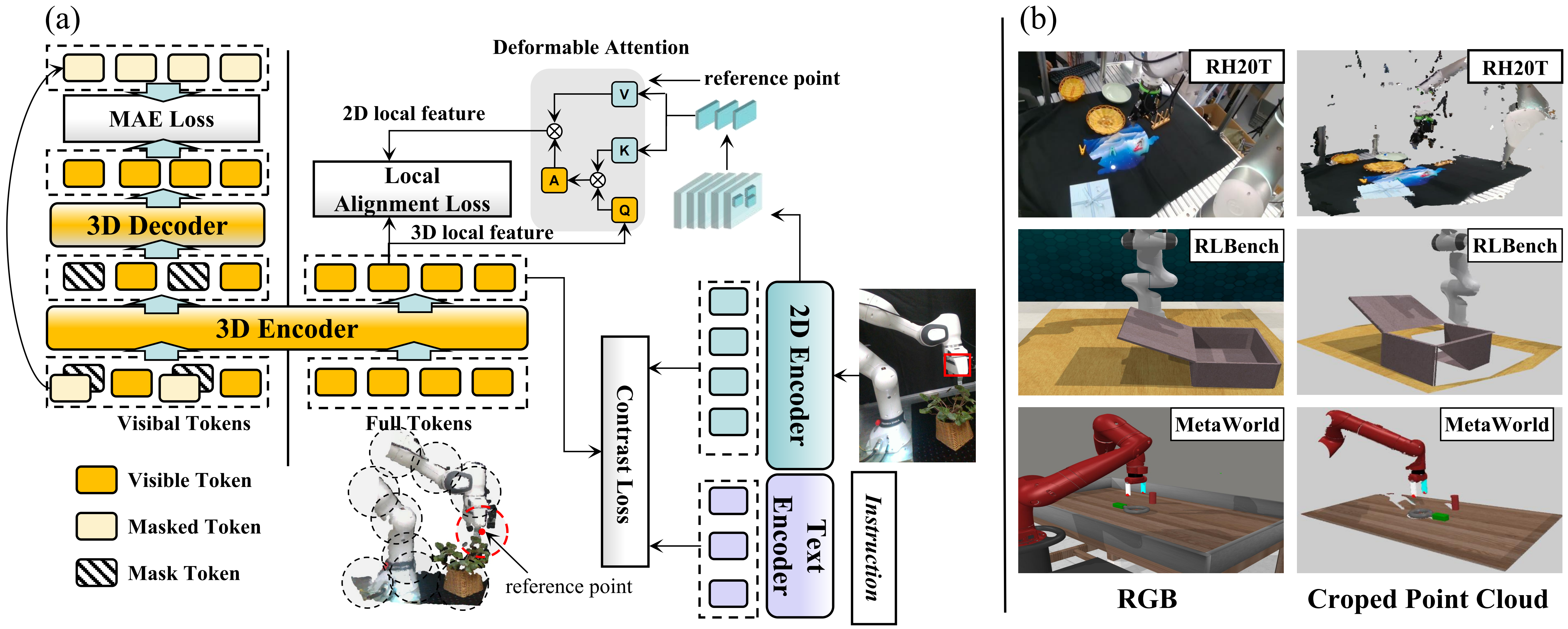
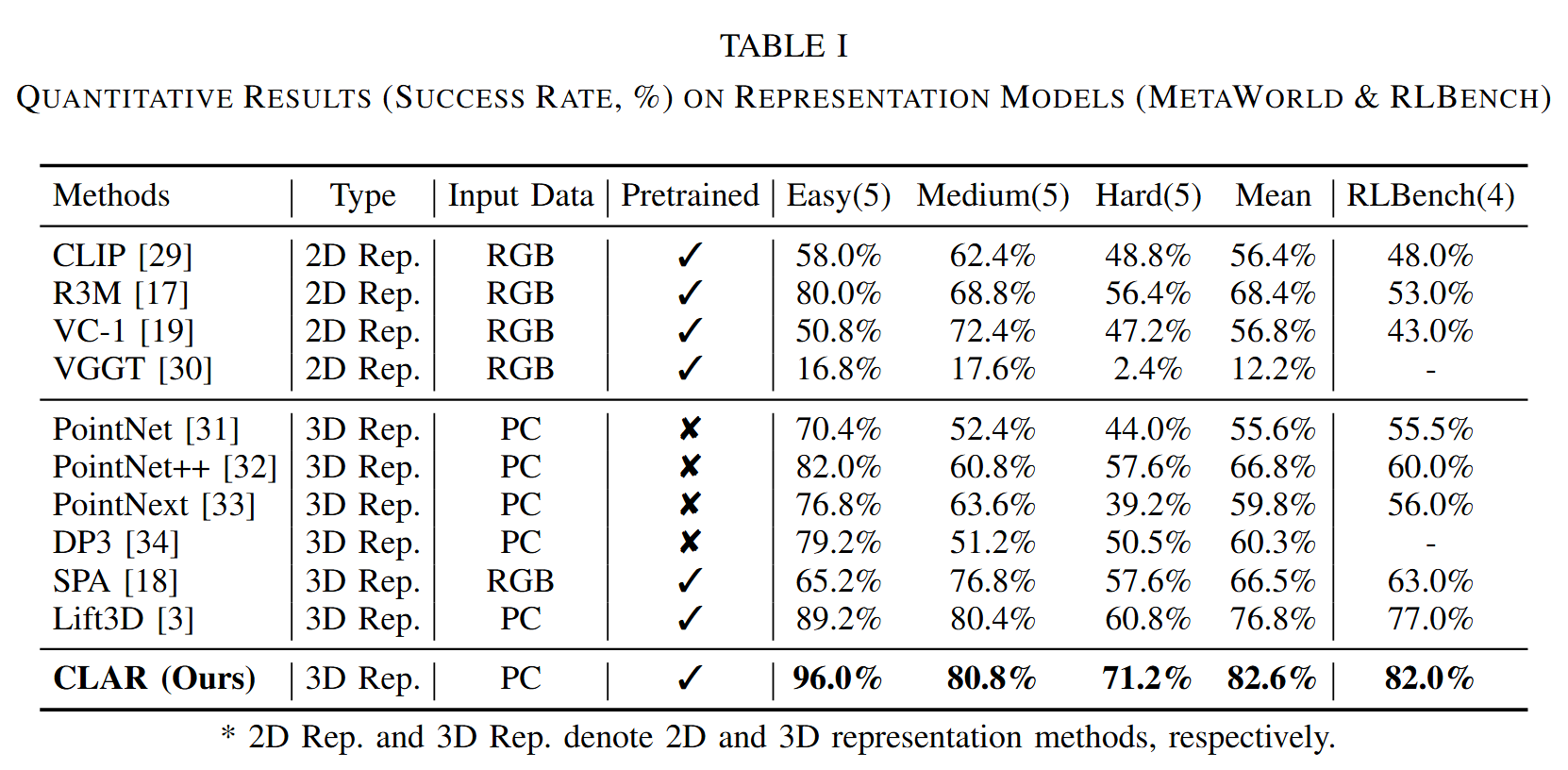
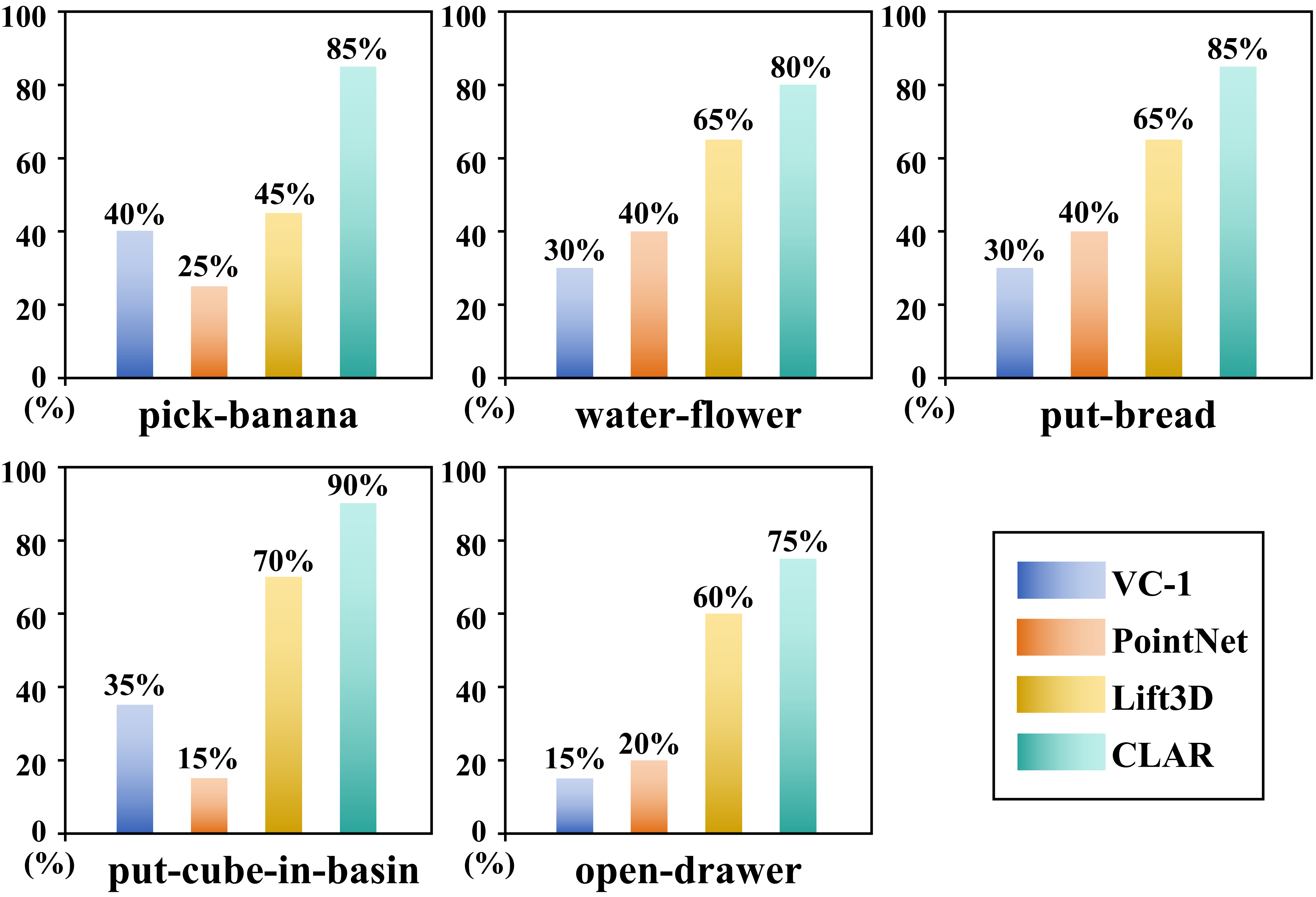
The spatial information inherent in 3D point clouds is crucial for robotic manipulation. However, existing 3D pre-training methods face a fundamental trade-off: Masked Autoencoding (MAE) excels at capturing spatial-geometric features but lacks semantics, whereas contrastive learning is ill-suited for the fine-grained details required for manipulation tasks.
To address these challenges, we propose CLAR, a novel 3D pre-training framework that synergizes global understanding with fine-grained local alignment. CLAR unifies MAE with global cross-modal contrastive learning and introduces an adaptive alignment mechanism leveraging deformable attention to force precise 3D-to-2D correspondences.